Depending on environment and goals, decisions have to be made regarding the components that will make up the final website. Some elements may already be in place (such as an identity server) and some elements may still be free to choose. This section aims at helping taking the right decisions.
Identity server
EPP 5.2 comes with a component named PicketLink IDM, which is made to adapt to store and retrieve users and groups from various identity servers. We can separate the different options into three:
-
Database: users, groups and their relationships are stored in a RDBMS database. Table names and column names can be changed, but the overall relationship between tables remains the same. This solution is particularly adapted to a new identity server that will handle thousands of users.
-
LDAP: users, groups and their relationships are stored in an LDAP (or ActiveDirectory) server, the directory structure can be adapted by configuration to the most common scenarios. This solution is particularly suited to infrastructures that already use an LDAP server, infrastructures that will share the server identity among multiple services (and the website being one of them) or for very large sets of users (millions). When using LDAP with large number of users, it is recommended to use LDAP tools to do the provisioning of users.
-
Custom: when retrieving users, groups and their relationship cannot be done by configuration, it is possible to use the Picketlink IDM SPI to implement the methods which control retrieving and storing user information.
Picketlink IDM also supports mix environments, which is very useful when an LDAP infrastructure is provided in a read-only mode. Since a website may need to store additional information about users (such as their preferred language or skin), it can combine LDAP and database services to retrieve users from LDAP and store additional properties in a database. During the calls to the identity API, the information from both sources will be transparently merged.
For more information about PicketLink IDM, please check the EPP 5.2 reference guide and the PicketLink IDM documentation.
Storage
The portal framework stores page compositions, portlet preferences, gadget code in a database through a Java Content Repository (JCR) API. A set of database servers and JDBC connectors are part of our quality assurance cycles and the certified environments are mentioned here.
It is important to choose one of the combinations or check with a Red Hat contact for specific environments that would differ from this list.
The database schema will be automatically created during the very first start up of a website and then it is required that the database users have sufficient rights to create tables. This privilege can be revoked after the initial start up, also the database content can be exported and imported in a new server. This makes the installation of the product very easy in most cases.
We do not provide additional recommendation to choose one database server over another as long as it is one of the certified environment.
As said earlier, content is stored through a JCR API, RDBMS aren't a great fit to store large files and it is possible to configure eXo JCR to store such files in the filesystem instead of a database, whereas metadata about the files would still be stored into the database. Note that if the website is running on a cluster, the filesystem will need to be accessible from all the nodes and a NFS solution needs to be set up. For more details see the notion of "value storage" in the reference guide.
Cluster
Clustering for failover or load-balancing requirements requires spending more time configuring it for your environment, we made it easy to handle common situations though. There is a cost associated with clustering (EPP 5.2 has some optimizations when running on a single node), but the product is designed to linearly scale up so that the same performance is added every time a new node is added. All critical parts are kept in sync among nodes and the less critical ones are left aside to achieve better performance. It will be equally critical that applications developed for the final websites pay the same attention when it comes to replicating data across a cluster of nodes.
The number of nodes will vary a lot depending on the applications developed and used on the final website. We recommend to do early performance analysis with tools such as JMeter, Grinder or similar to measure the impact of heavy loads.
It is usually recommended to run a cluster to achieve high availability.
SSO
If a website is a part of a more global infrastructure with various components (the website being one of several), it may be in the benefit of users to use a Single-Sign-On solution. Various SSO solutions are supported by EPP 5.2 as seen here. In some cases it can be better to have the token manager service on a specific server.
Summary
By now you should know what infrastructure you will need:
-
A database
-
Optionally LDAP, depending on your choice
-
Optionally NFS, depending on the configuration (mandatory on a cluster with default settings)
-
Optionally an SSO token service
-
Optionally a cluster of nodes
Here is an example of the simplest set-up:
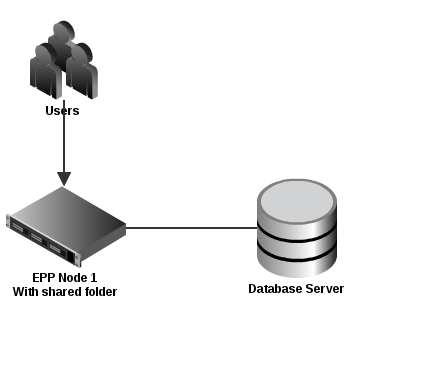
simpleinfra
Here is an example of a more complex setup:
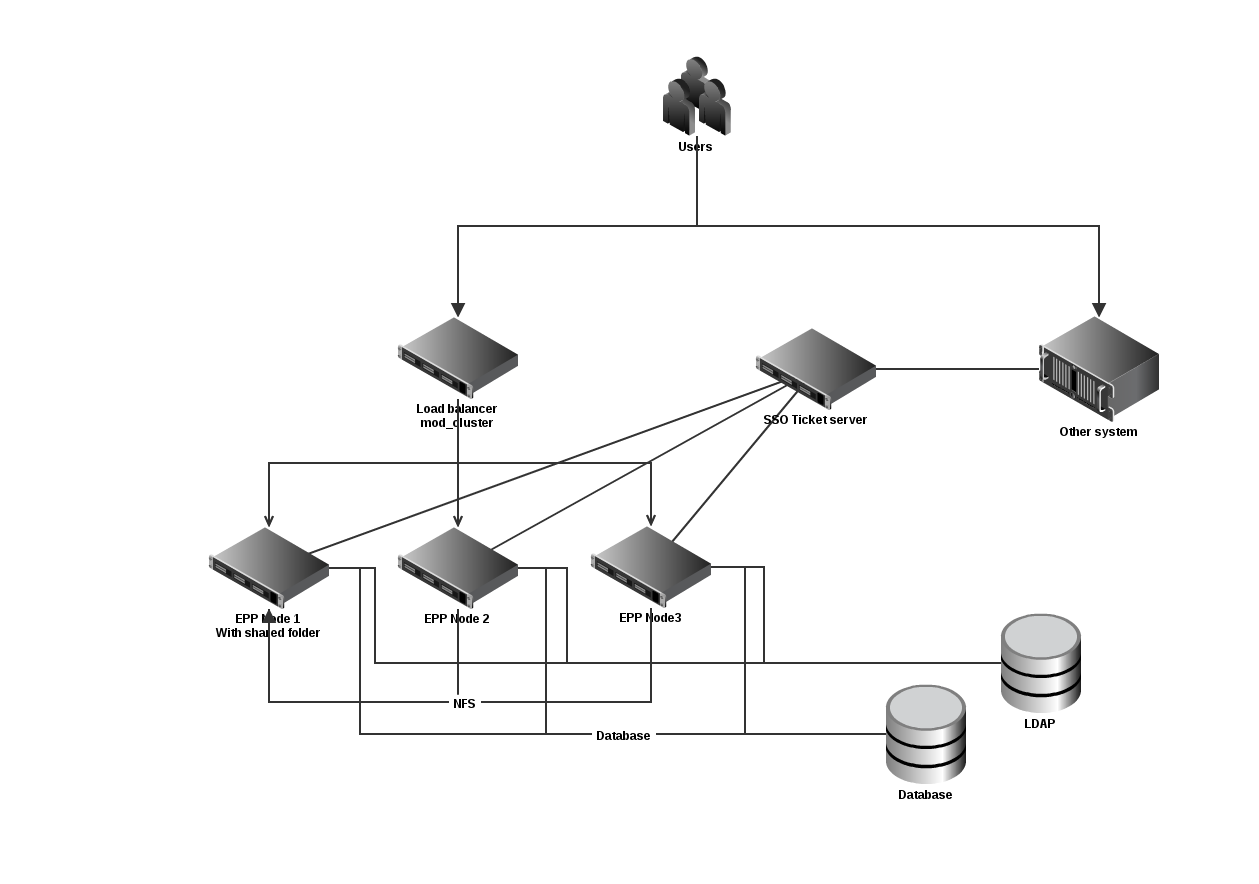
complexinfra